My Work
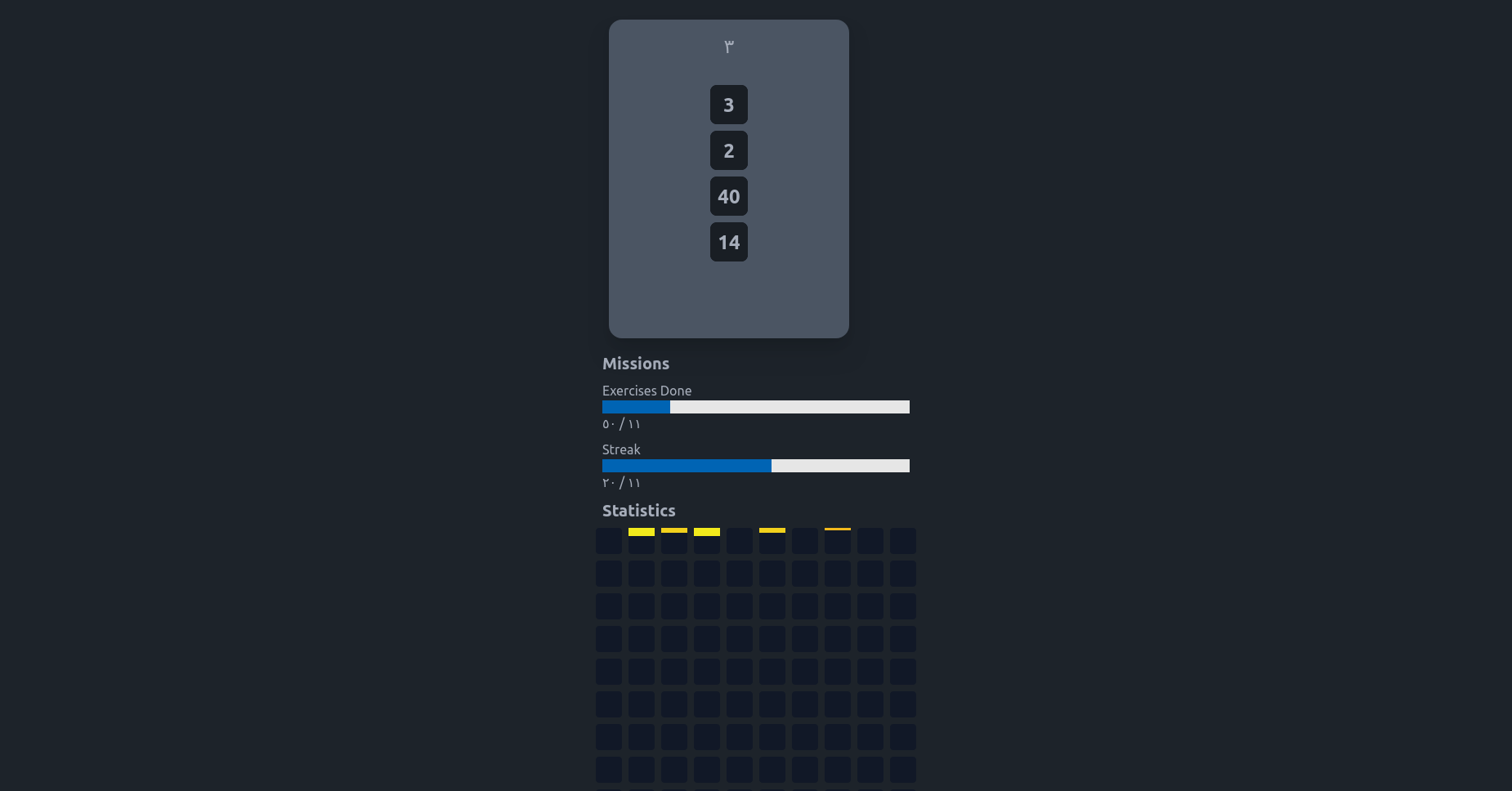
Arabic Number Practice
An online trainer to practice counting in Egyptian
🇪🇬
🇬🇧
mvp
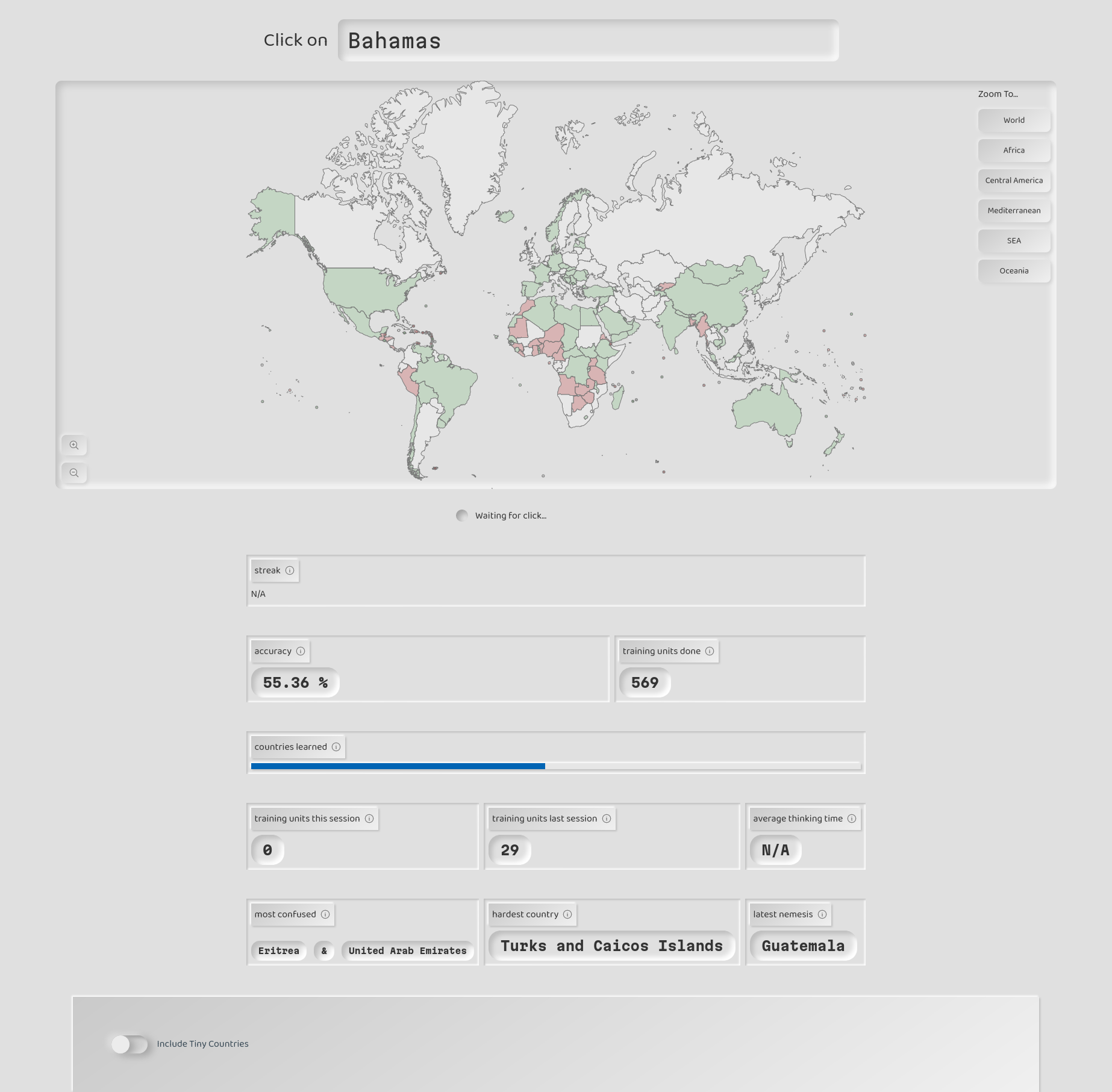
Map Practice
A Spaced Repetition web game about placing countries
mvp
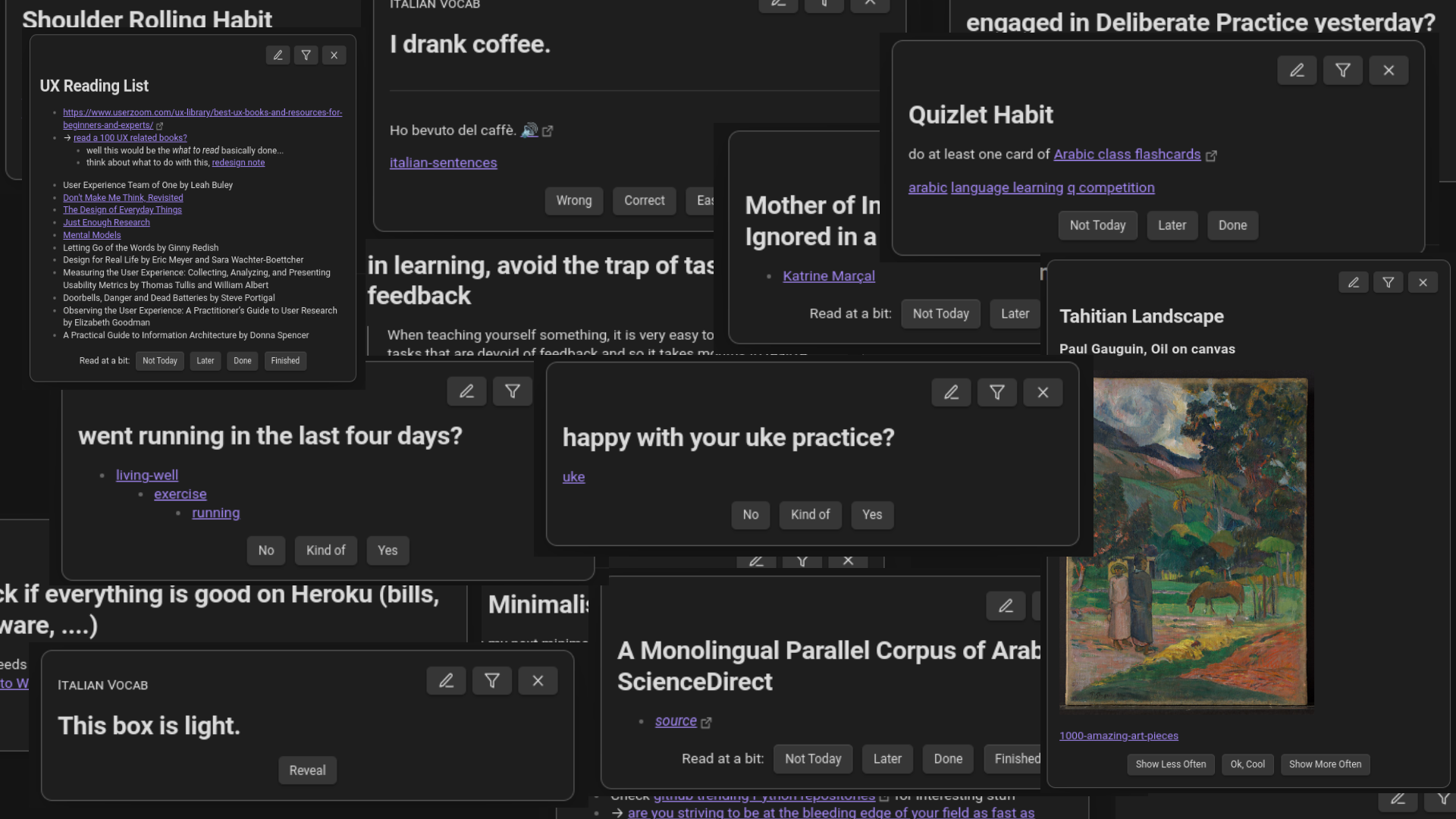
Obsidian — The Queue
An Obsidian.md plugin randomly exposing you to your notes. Supports habits, to-dos, spaced repetition flashcards, iterative reading and more.
mvp
All My Projects
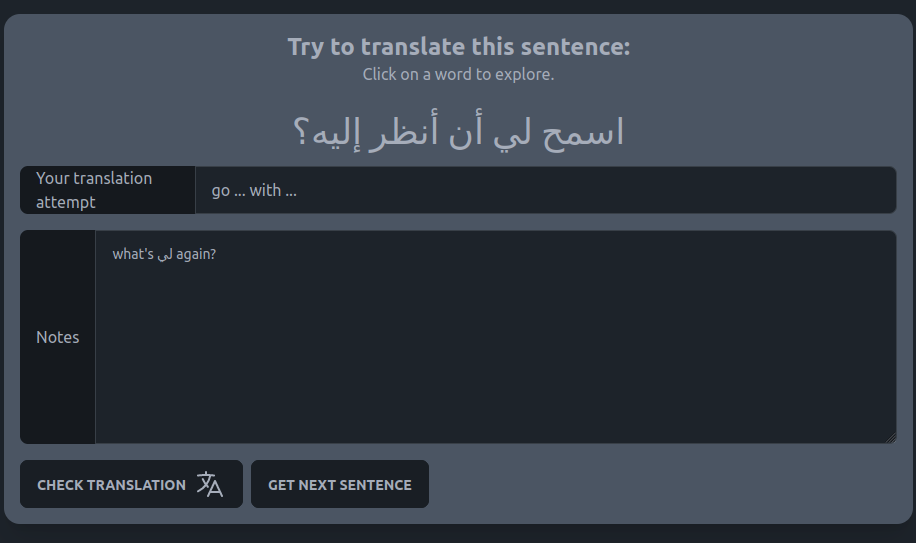
Arabic Syllables Pronunciation trainer
Practice Arabic by saying simple words out loud
🇪🇬
🇬🇧
mvp
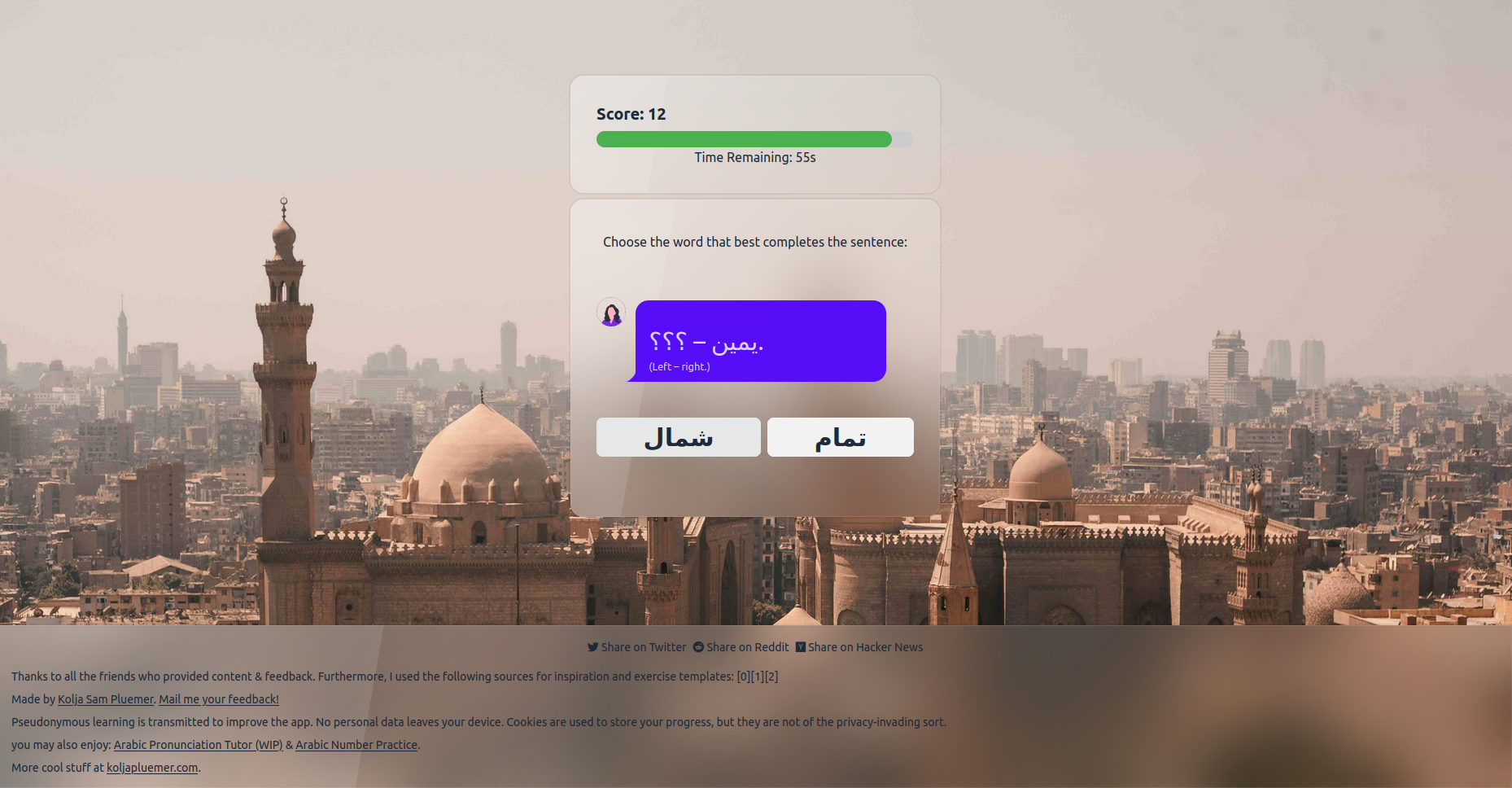
Basic Egyptian Sentences
A timed Spaced Repetition web game about Cairo survival Arabic
🇪🇬
🇬🇧
mvp
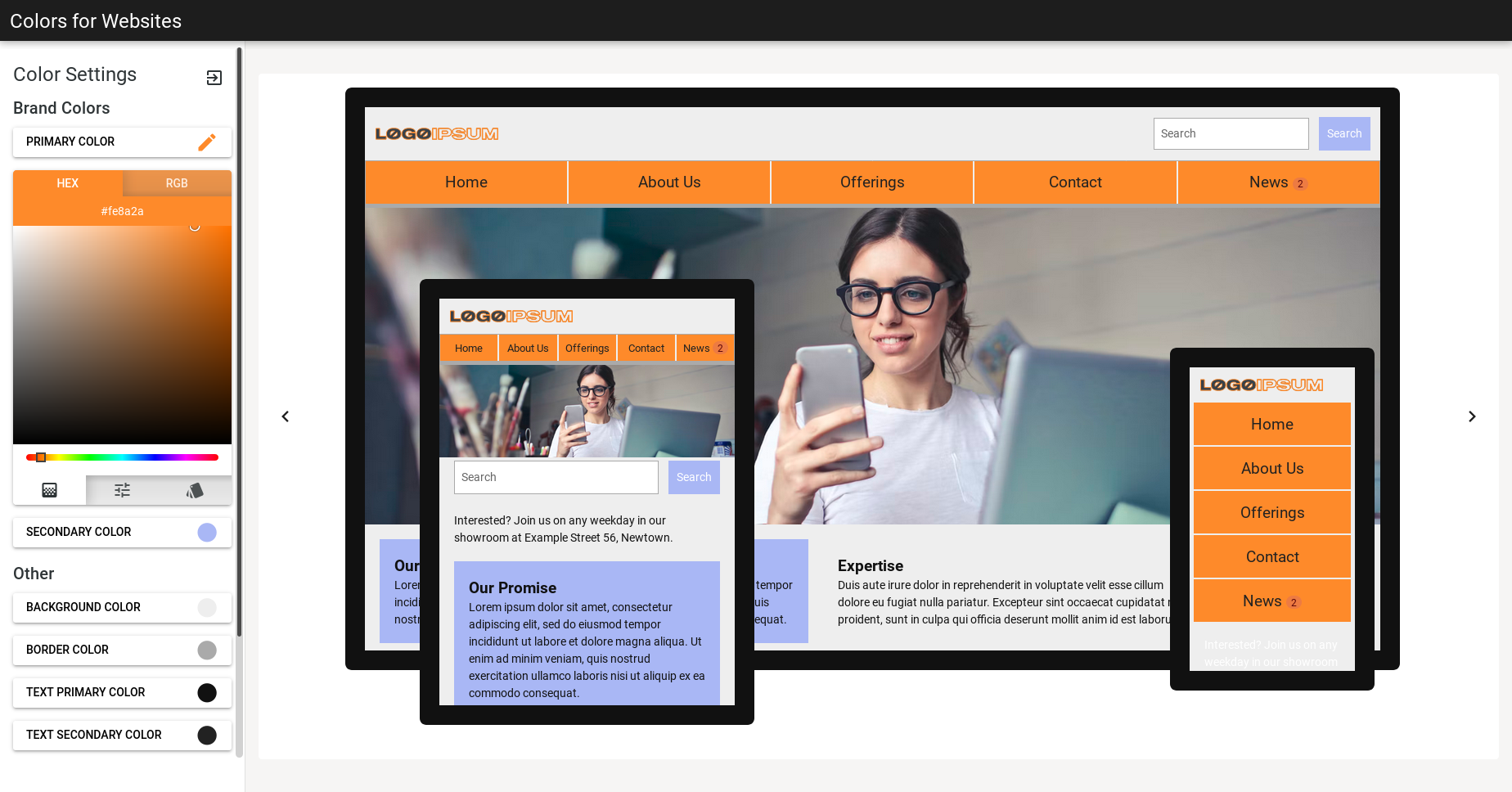
Colors for Websites
Color palette generator for real websites
mvp
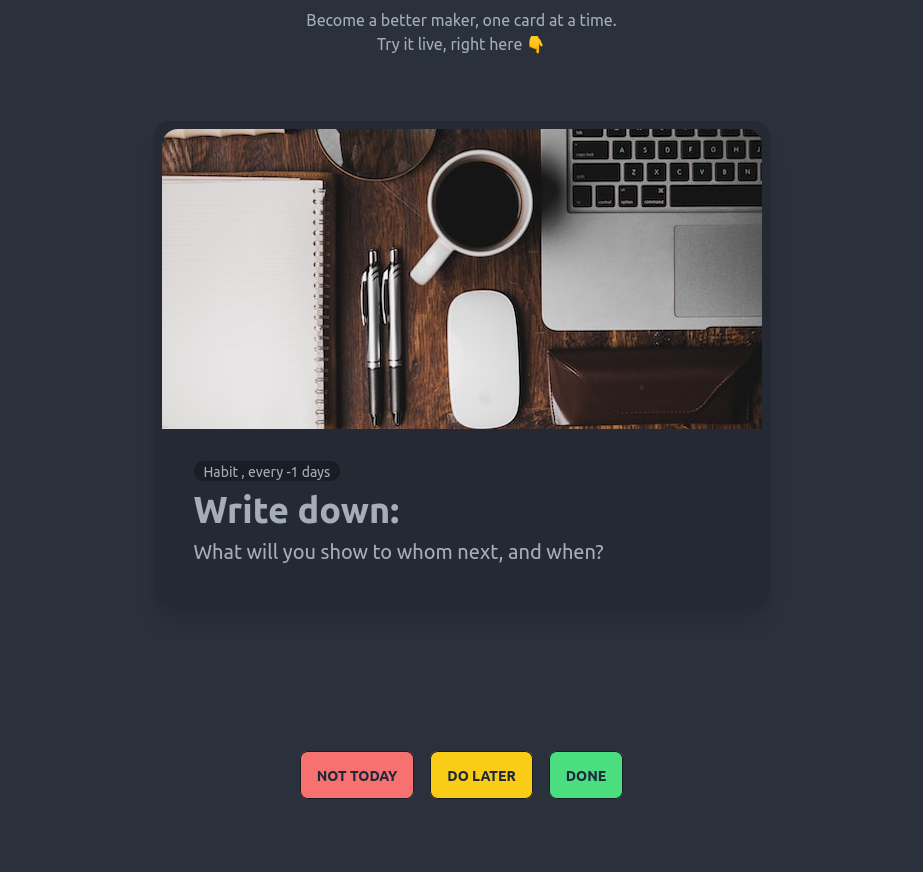
The Maker's Walk
Habits & knowledge for the overwhelmed entrepreneur
shuttered
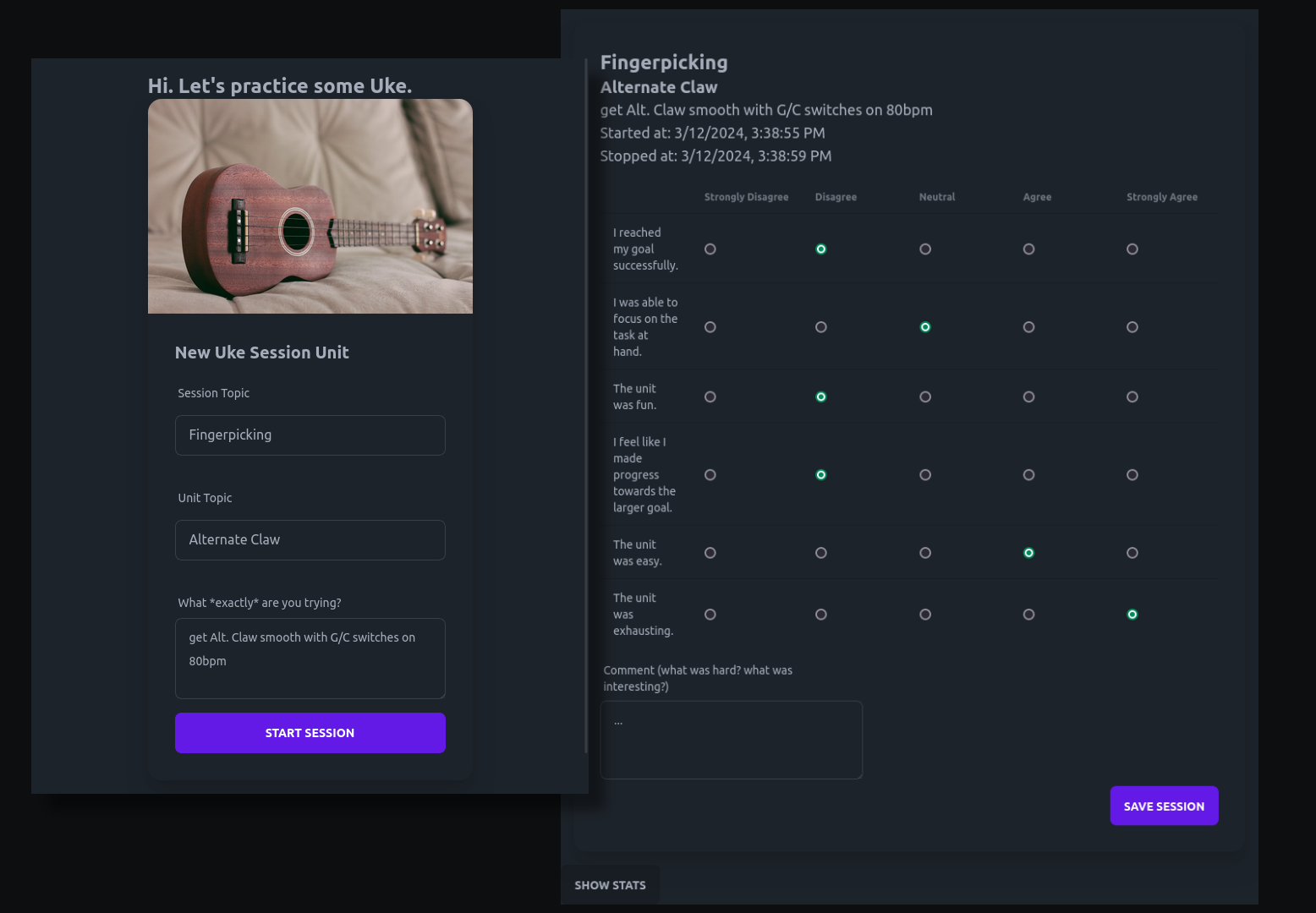
Ukulele Deliberate Practice Logger
Improve your ukulele skills with targeted practicing
alpha
Climate Stripes Localized
Recreating a Climate Change Visualization
🇩🇪
done
